OfflineLLM rappresenta un cambio di passo per chi cerca un’esperienza AI realmente privata su Android. Tutto il processo di inferenza avviene in locale grazie a llama.cpp, eliminando completamente qualsiasi dipendenza da servizi remoti. L’assenza del permesso INTERNET nell’app non è un dettaglio: significa che non esiste alcuna possibilità tecnica di inviare dati all’esterno.
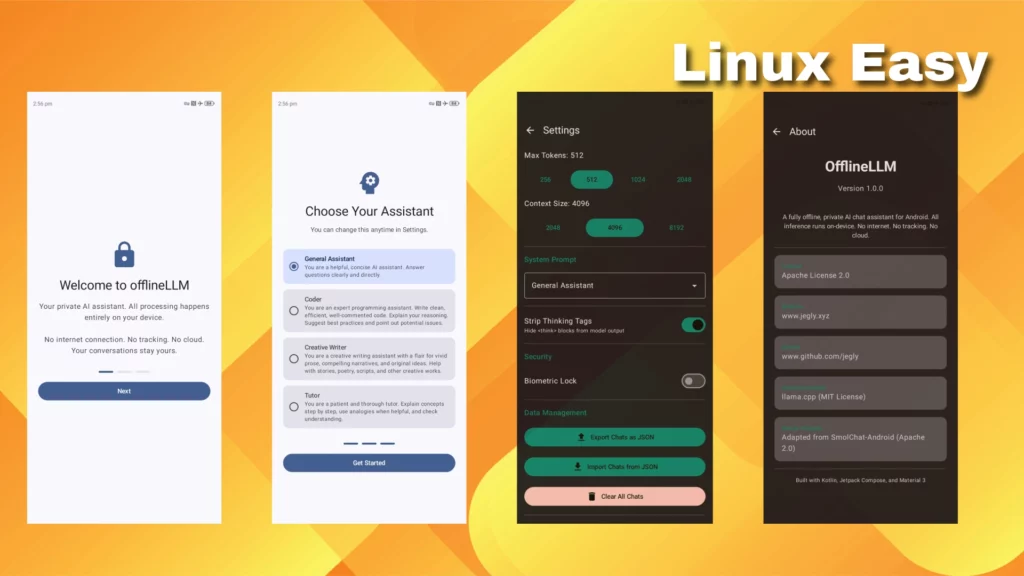
Questo approccio è particolarmente interessante per sviluppatori, sysadmin e utenti Linux abituati a controllare ogni aspetto del proprio ambiente. OfflineLLM porta la stessa filosofia su mobile, con un controllo completo sui modelli utilizzati e sui dati generati.
Funzionalità avanzate e controllo totale dei modelli
Uno dei punti di forza è la gestione flessibile dei modelli in formato GGUF. È possibile importarli manualmente da piattaforme come Hugging Face, scegliendo il compromesso ideale tra prestazioni e qualità.
L’app supporta modelli moderni come Gemma 4 e Qwen 3.5, con diverse dimensioni pensate per adattarsi a dispositivi con RAM limitata fino a smartphone più performanti.
Le opzioni di configurazione sono tutt’altro che basilari:
- regolazione fine di temperatura, Top-P, Top-K e repeat penalty
- gestione di prompt di sistema personalizzati (coder, tutor, creativo)
- streaming token-by-token per risposte fluide
- supporto TTS tramite engine Android
Interessante anche la funzione di rimozione automatica dei tag <think>, utile con modelli reasoning-based per ottenere output più puliti.
Dal punto di vista delle performance, i risultati sono concreti: circa 25 token al secondo su dispositivi economici e oltre 60 token su fascia alta.
Questo rende OfflineLLM utilizzabile anche in scenari reali, non solo come demo tecnica.
Installazione e scenari d’uso pratici
L’installazione è semplice ma richiede il sideload dell’APK, quindi è necessario abilitare manualmente l’installazione da fonti sconosciute. Una volta avviata, l’app guida l’utente nell’importazione dei modelli.
Dal punto di vista pratico, OfflineLLM si presta a diversi utilizzi:
- ambiente di sviluppo offline per test rapidi
- assistente personale senza rischi di leak dati
- strumento educativo per sperimentare con LLM
- utilizzo in contesti senza connettività
La gestione delle conversazioni è completa: cronologia esportabile in JSON, ricerca interna e backup locale. Non manca nemmeno la sicurezza con cifratura delle impostazioni e blocco biometrico opzionale.
In prospettiva, l’arrivo del supporto RAG con memoria persistente potrebbe trasformare OfflineLLM in una soluzione ancora più interessante per workflow avanzati completamente offline, mantenendo sempre il controllo totale sui dati e sull’infrastruttura AI personale.